Loading...

Loading...
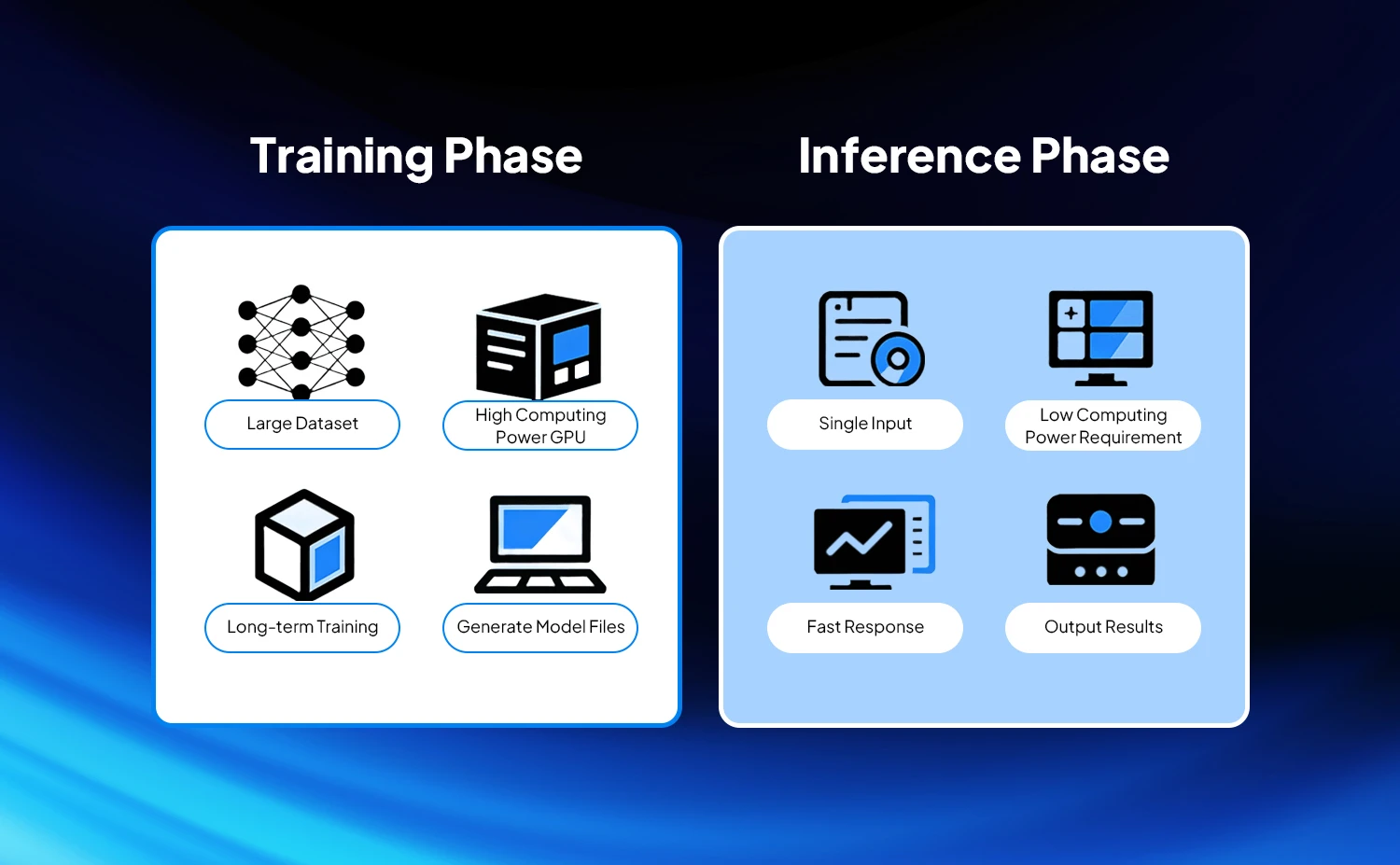
The Difference Between AI Training and Inference
AI training and inference are two interconnected but fundamentally different stages in the AI workflow: training is the process of "teaching the model skills," while inference is the process of "enabling the model to apply those skills." They differ significantly in their goals, processes, and resource requirements, which directly determines their different demands on the network.
In simple terms, training is like a marathon requiring continuous collaboration — pursuing overall throughput and stability; inference is like a 100-meter sprint, emphasizing low latency and efficient response. The specific differences are elaborated across the following dimensions.
Core Objective Differences
AI Training — The core principle is to use massive amounts of labeled data to iteratively optimize model parameters (weights), enabling the model to master specific skills such as recognition, generation, and prediction — ultimately achieving higher accuracy and generalization ability. The training process does not pursue the speed of a single computation, but focuses on the efficiency of massive parallel computing and job completion time (JCT) to avoid wasting GPU resources due to network bottlenecks.
AI Inference — The core idea is to use a pre-trained model to quickly predict new, unlabeled data and output results. Inference does not involve parameter updates; it pursues low latency, high concurrency, and high availability to ensure that end users (such as apps and mini-programs) receive quick responses. In scenarios such as ChatGPT generating replies, real-time road condition recognition for autonomous driving, and facial recognition unlocking, latency directly affects the user experience.
Differences in Computation Process
AI Training — The algorithm employs a bidirectional process of forward propagation and backward propagation. Forward propagation calculates the error between the model output and the real label, while backward propagation transmits the error in reverse to update the parameters of each layer. The entire process requires saving a large number of intermediate activation values and requires multiple GPUs to work together to complete gradient synchronization, All-Reduce, and other collective communication operations — resulting in massive data interaction.
AI Inference — This is a one-way process requiring only forward propagation. Input data is directly output as a prediction result after model computation, with no need for backpropagation or parameter updates. The amount of data interaction is much smaller than during training, and inputs are mostly small batches or even single data points, making the process simpler.
Resource Demand Differences
AI Training — Extremely high hardware resource requirements, demanding large-scale GPU clusters (hundreds or even thousands of units) working together. Each GPU requires large memory (to store model parameters and intermediate data), and GPUs must interact with each other at high frequency and speed. The network becomes the core bottleneck restricting training efficiency. When the number of GPUs reaches a certain scale, network latency and packet loss can directly lead to slower training convergence or even task interruption.
AI Inference — Resource requirements are relatively modest and can be met using a single GPU, small-scale multi-GPU clusters, or dedicated inference chips such as TPUs and FPGAs. Memory requirements only need to accommodate model loading and single forward computation. Data interaction is mainly north-south traffic from terminal to inference node. Network bandwidth requirements are lower than those for training, but sensitivity to latency is higher.
Differences in Network Traffic Characteristics
AI Training — Traffic consists primarily of east-west flows (data exchange within the GPU cluster and between nodes). This traffic is characterized by high bandwidth, high concurrency, and strong bursts — especially during the gradient synchronization phase, which generates short-term traffic spikes. Lossless transmission is critical: AI training networks cannot tolerate packet loss and must keep GPUs continuously running. Packet loss can result in anything from slowed training and decreased accuracy to cluster freezes and task crashes.
AI Inference — Traffic is mainly north-south (data interaction between end users and inference nodes, and between inference nodes and storage). Traffic is relatively stable with moderate bandwidth requirements, but low latency and low jitter are essential — particularly in real-time inference scenarios such as autonomous driving and live AI effects. Latency must be controlled in the millisecond or even microsecond range; otherwise, the service becomes unavailable.
Deployment Scale and Topology Differences
AI Training — Large-scale deployments typically require hundreds to thousands of GPU servers forming a cluster. The network topology must support large-scale horizontal scaling, often employing a Clos Spine-Leaf or DDC (Distributed Disaggregated Chassis) architecture to ensure full-bandwidth communication across the cluster even after expansion, without significant bottlenecks.
AI Inference — Deployment scale is flexible, ranging from dozens to hundreds of nodes depending on business needs. The topology is relatively simple, mostly adopting a two-layer architecture of access layer and aggregation layer, focusing on stability and low latency for terminal access — without the need for complex large-scale interconnection.
Differences in Core Switch Requirements
AI Training — Core switch requirements are high bandwidth, low latency, lossless transmission, and high scalability. Switches must support collaborative communication across large-scale GPU clusters, prevent the network from becoming a bottleneck for training efficiency, and provide congestion control and manageability to reduce operational complexity at scale.
AI Inference — Core switch requirements are low latency, high concurrency, high availability, and low cost. Switches must support high-frequency access from end users, ensure fast and stable inference responses, adapt to flexible deployment scales, and keep overall operational costs controlled.
AI Training vs. AI Inference — Comparison at a Glance
| Dimension | AI Training | AI Inference |
|---|---|---|
| Core Objectives | Optimize model parameters to improve accuracy and generalization ability | Quickly output prediction results to ensure user experience |
| Computation Process | Forward + backward propagation; bidirectional interaction | Forward propagation only; unidirectional output |
| Resource Requirements | Large-scale GPU clusters with high memory and compute | Single GPU or small-scale cluster; moderate resource requirements |
| Traffic Characteristics | Primarily east-west; high bandwidth, high concurrency, strong bursts | Primarily north-south; stable traffic, high demand for low latency |
| Network Demands | High bandwidth, low latency, lossless transmission, high scalability | Low latency, high concurrency, high availability, low cost |
| Topology Requirements | Clos/DDC architecture supporting large-scale expansion | Two-tier architecture for flexible deployment |
AurCore Solutions

For AI training, AurCore offers a 32×400G high-speed switch supporting RoCEv2 and PFC+ECN. Built for Clos architecture, it matches the collaborative needs of large-scale GPU clusters and prevents the network from becoming a training bottleneck — meeting requirements for high bandwidth, lossless transmission, and high scalability.

For AI inference, AurCore offers a series of high-speed switches — 32×100G and 48×25G+8×100G — specifically designed for inference workloads. These switches optimize forwarding latency and concurrent processing capabilities, control costs, and adapt to flexible deployment scales and terminal access requirements, satisfying inference network demands for low latency, high concurrency, and high cost-effectiveness.